Agentic AI,
Artificial Intelligence & Machine Learning,
Next-Generation Technologies & Secure Development
New Research Reveals AI Agents Depend on Human Oversight, With Performance Potential Over Time

AI agents are transitioning from theoretical constructs to practical applications within enterprises. Professionals are integrating these agents into critical business functions, including financial assessments, document evaluations, and drafting processes. However, a pressing issue still lingers: What metrics can we rely on to gauge the effectiveness of AI agents?
See Also: On-Demand | NYDFS MFA Compliance: Real-World Solutions for Financial Institutions
A recent benchmark study, termed the AI Productivity Index for Agents (APEX-Agents), sought to probe the capabilities and limitations that concern CIOs and COOs. By utilizing tasks curated by industry experts such as investment banking analysts and corporate lawyers, the research assessed the extent to which AI agents can undertake complex, cross-functional tasks typical of knowledge-intensive sectors.
Results revealed subpar outcomes. AI agents achieved a success rate of merely 24% on initial attempts, as measured by the Pass metrics for machine code execution. Although these agents demonstrate some utility, this figure necessitates a reconsideration of their operational implementation.
The implications of this 24% success rate raise essential questions: What enterprise tasks are AI agents capable of managing in the current landscape? A closer inspection of the study provides clarity.
Evaluating AI Agents’ Capabilities
The productivity index encompassed 480 tasks across 33 unique environments across investment banking, management consulting, and corporate law. Each environment includes approximately 166 files and grants access to critical workplace essential tools such as documents, spreadsheets, presentations, PDFs, emails, calendars, and code execution.
To craft relevant scenarios and tasks, Mercor, an AI recruitment firm, surveyed 227 professionals, inclusive of 58 financial analysts, 77 management consultants, and 92 lawyers, each averaging 10.8 years of experience. The study aimed to determine whether AI agents could perform at levels comparable to junior and mid-tier professionals, with the average task requiring one to two hours for completion.
“Our goal was to uncover if current AI agents can execute economically valuable tasks,” stated Mercor CEO Brandon Foody. “Are they equipped to function optimally within real software environments and produce deliverables ready for clients? We discovered that even the top-performing models struggle with the intricacies of real-world challenges, often failing to meet the necessary production standards.”
Assessing Acceptability Levels
The leading model assessed achieved a Pass@1 score of 24%, indicating it met all task parameters in roughly one out of four attempts. The second-best model logged a score of 23%, while others trailed between 18% and 20%. Notably, open-source models underperformed, with success rates dipping below 5%.
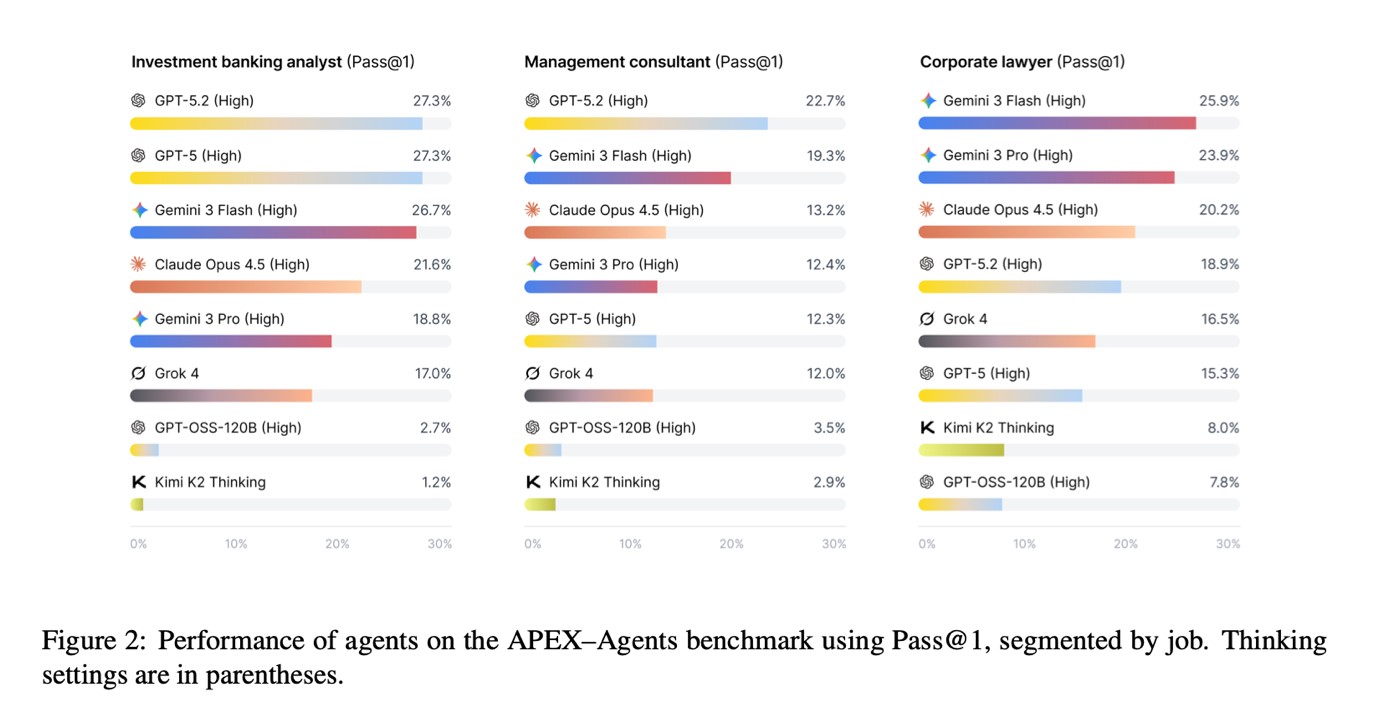
Despite the apparent failures, the stringent Pass@1 standard is essential for evaluating performance, as tasks adhere to explicit, stringent guidelines. Any deviation from these criteria is classified as a failure, reflecting client-facing realities where even partial success holds limited value.
However, when AI agents are permitted multiple attempts, their performance sees improvements, with the best agents achieving success rates between 36% and 40% after eight attempts. This discrepancy indicates the underlying potential, though it also highlights issues with execution.
Consistency remains a significant hurdle. When tasked with maintaining success across eight repetitions, performance plummeted, with the highest model achieving only 13.4%. Such variability hampers the agents’ viability for real-world deployment without oversight and supervision.
One insightful analysis from the APEX-Agents study revolves around understanding failures. A failed attempt does not inherently denote that the model lacks value. Even unsuccessful tries can yield partial results, indicating that these agents frequently manage significant aspects of tasks even when they fail to meet all criteria.
This is corroborated by mean task scores, nearing 40% for peak-performing agents, suggesting that these agents can indeed produce acceptable work products.
For professionals in AI, these findings prompt a reevaluation of productivity metrics. AI agents may not autonomously complete tasks but can significantly minimize human effort, accelerate workflows, and open opportunities for review and validation.
Challenges in Execution
The primary challenges facing AI agents are not rooted in domain knowledge or cognitive reasoning. Most shortcomings arise during execution and orchestration. For instance, AI agents often surpassed the benchmark’s 250-step limitation, highlighting inefficient task management. They struggled with file creation or editing, instead leaning towards text generation, and frequently executed excessive tool calls without progressing toward a solution.
The findings also demonstrated that the most resource-intensive AI agent, which utilized more tokens and steps, encountered more timeouts. This data indicates that greater computational resources do not equate to better outcomes. Effective executions generally involve simpler task sequences necessitating focused operations.
This insight holds critical relevance for enterprise applications, emphasizing that the true bottleneck lies in managing real systems and artifacts across complex workflows.
Capabilities of AI Agents
The insights from this research imply that most current AI agents excel in specific, well-defined segments of professional tasks rather than independently managing entire assignments. They perform reasonably well in areas such as data extraction and transformation, initial analyses and summaries, updating existing models under precise instructions, and exploring various solution paths with retries.
Nonetheless, agents face notable challenges delivering consistent outputs without guidance and maintaining stability throughout extended workflows while manipulating files without errors.
This reality suggests that early adopters are better positioned to leverage AI agents as extensions of human-led workflows, rather than relying on them for complete autonomy.
Shifting Perspectives on Productivity
Do these findings indicate that AI agents are overhyped? They certainly reveal a need for more rigorous measurement of vendors’ productivity claims. A 24% success rate doesn’t equate to failure; instead, it highlights the probabilistic nature of their operation, suggesting that businesses need to adapt their workflows to accommodate these limitations.
The benchmark does illustrate that agents can contribute effectively to complex tasks, provided their limitations are acknowledged and mitigated through structured task designs. While there are opportunities for productivity gains, these improvements are likely to be inconsistent and highly contextual.
The essential takeaway for technology leaders is that AI agents currently require human oversight to function optimally, but with appropriate expectations and the willingness to refine their performance, the deployment of agentic AI can gradually evolve toward more effective task completion.