Key Insights:
- Cisco researchers identified significant security vulnerabilities in several popular open-weight AI models.
- Multi-turn adversarial attacks were found to be substantially more effective than single interactions.
- These findings highlight critical concerns regarding AI safety, data privacy, and the integrity of AI models.
Cisco has uncovered critical security vulnerabilities in several leading open-weight large language models (LLMs), pointing out that cybercriminals could exploit these flaws using only a few well-crafted prompts. These vulnerabilities leave AI systems susceptible to manipulation, misinformation, and potential data breaches, heightening the risk for organizations relying on these technologies.
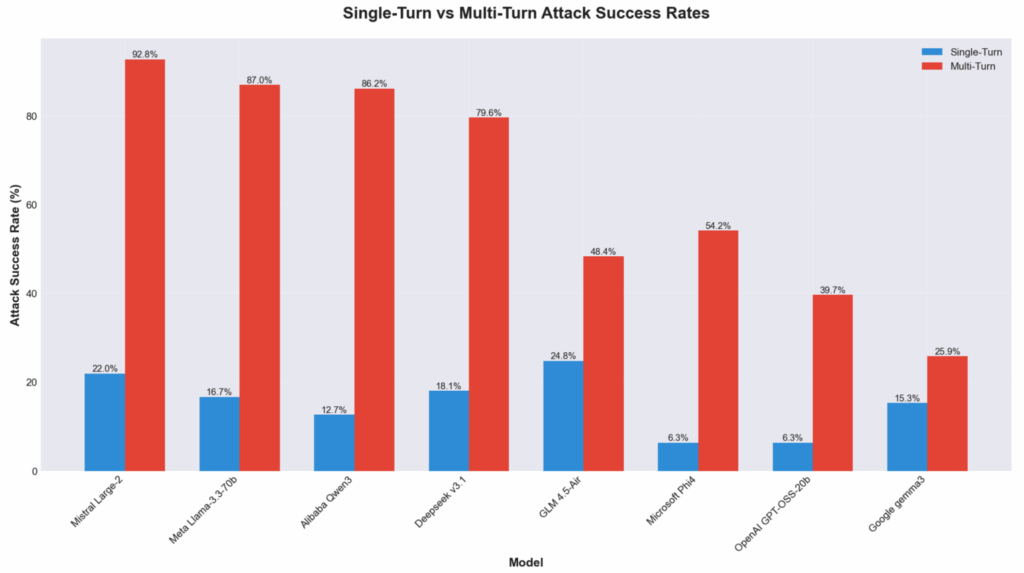
In a comprehensive security assessment, Cisco’s researchers evaluated eight prominent open-weight LLMs, including models from Alibaba, DeepSeek, Google, Meta, Microsoft, Mistral, OpenAI, and Zhipu AI, using Cisco’s AI Validation platform. This comparative analysis aimed to identify weaknesses that could be leveraged in cyber-attacks.
The Mechanics of Multi-Turn Attacks on Open-weight Models
The research revealed that publicly accessible AI models are prone to adversarial manipulation. Notably, multi-turn adversarial attacks—where AI models are manipulated through a series of conversational prompts—showed success rates two to ten times higher than single-turn attacks. The Mistral Large-2 model ranked highest in vulnerability, achieving a 92.78% success rate in these multi-turn scenarios.
Models employing capability-first strategies, exemplified by Meta and Alibaba, exhibited more considerable discrepancies between their susceptibilities to single and multi-turn attacks. Alternatively, models aligned more effectively with safety protocols, like those from Google and OpenAI, maintained a more balanced security profile, suggesting variations in their defense mechanisms.
Real-World Implications of AI Vulnerabilities
Cisco’s research emphasized the heightened risk of threats such as misinformation, manipulation, and malicious code generation. These threats were found to be consistently successful across various models, although effectiveness varied according to the model’s design and defenses. The researchers underscored that the vulnerabilities detected could compromise sensitive data and user privacy.
The potential for serious repercussions in real-world applications is significant. The report highlights possible risks, such as sensitive data breaches, content manipulation that undermines data integrity, ethical violations stemming from biased outputs, and operational disruptions in systems like chatbots and decision-support tools.
Recommendations for Strengthening AI Security
In light of these findings, organizations are urged to implement robust security measures for open-weight AI models. Conducting adversarial testing is critical; regularly probing these models with challenging prompts can help identify vulnerabilities before deployment. Establishing context-aware guardrails is vital to ensure safe interactions, particularly during multi-turn conversations where the risk of exploit is exacerbated.
Additionally, organizations should engage in red teaming exercises to simulate real-world attack scenarios, providing insights into model behavior under stress. Ongoing real-time monitoring is essential to detect and address unsafe behaviors swiftly, ensuring models are chosen based on both their performance and security postures. By strengthening these defenses, businesses can better safeguard their operations against the evolving landscape of cyber threats.